
การเรียนรู้เชิงลึก (Deep learning) เป็น machine learning ประเภทหนึ่งที่เกี่ยวข้องกับการฝึกอบรมเครือข่ายประสาทเทียม(Artificial Neural Networks)ในชุดข้อมูลขนาดใหญ่(dataset) เครือข่ายประสาทประกอบด้วยชั้นของโหนดที่เชื่อมต่อกัน ซึ่งได้รับแรงบันดาลใจจากโครงสร้างของสมองมนุษย์ แต่ละโหนดในโครงข่ายประสาทเทียมทำการคำนวณอย่างง่ายบนข้อมูลอินพุตและส่งผ่านผลลัพธ์ไปยังโหนดถัดไปในเครือข่าย
Deep learning
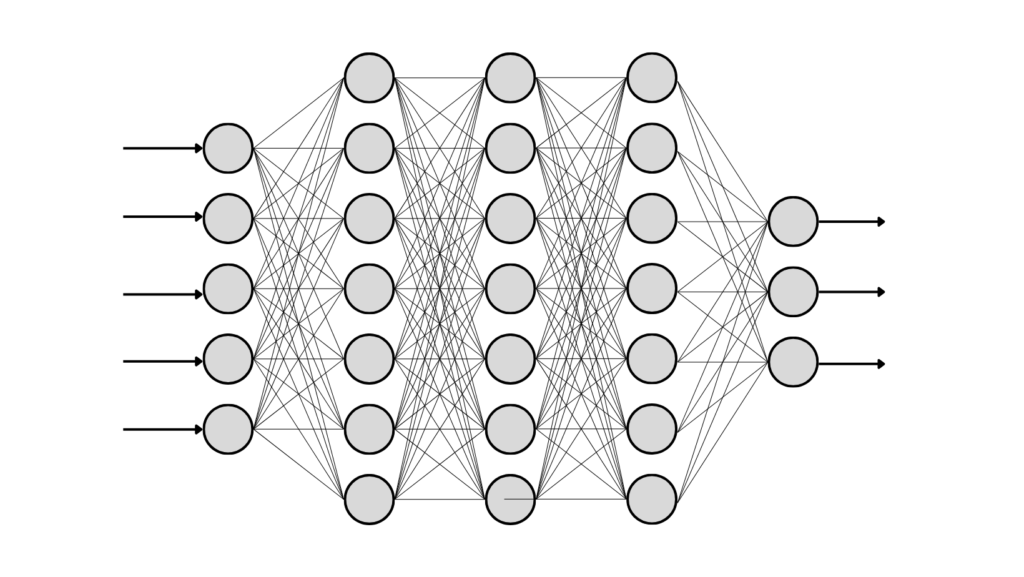
อัลกอริทึมของDeep learningสามารถเรียนรู้รูปแบบและความสัมพันธ์ที่ซับซ้อนในข้อมูลโดยการฝึกอบรม node ที่เชื่อมต่อกันหลายชั้น แต่ละเลเยอร์จะประมวลผลข้อมูลอินพุตและส่งต่อไปยังเลเยอร์ถัดไป จนกระทั่งเลเยอร์สุดท้ายสร้างเอาต์พุต
การเรียน Deep learning มีประโยชน์อย่างยิ่งสำหรับงานที่ต้องการนามธรรมในระดับสูง เช่น การรู้จำภาพและคำพูด การประมวลผลภาษาธรรมชาติ และการตัดสินใจด้วยตนเอง มีหน้าที่รับผิดชอบต่อความก้าวหน้าล่าสุดของ AI และนำไปสู่การปรับปรุงประสิทธิภาพของระบบแมชชีนเลิร์นนิงจำนวนมาก
node เป็นหน่วยการสร้าง(building block)ของโครงข่ายประสาทเทียม(neural network) โหนดนั้นเป็นหน่วย unit ย่อยที่ประกอบกันเป็นเครือข่ายและเชื่อมต่อกับโหนดอื่น ๆ ผ่านเส้นทางที่เรียกว่า edge แต่ละโหนดรับอินพุตจากโหนดอื่น ดำเนินการทางคณิตศาสตร์ แล้วส่งออกไปยังโหนดอื่น โหนดและเอดจ์ทำงานร่วมกันเพื่อประมวลผลและแปลงข้อมูลอินพุต ทำให้เกิดเอาต์พุตหรือการทำนายในท้ายที่สุด
edge เป็นเส้นทางที่เชื่อมต่อโหนดในโครงข่ายประสาทเทียม แต่ละขอบมี weight ซึ่งเป็นค่าที่แสดงถึง strength ของการเชื่อมต่อระหว่างสองโหนด weightเหล่านี้จะถูกปรับระหว่างกระบวนการฝึกอบรมเพื่อเพิ่มประสิทธิภาพการทำงานของเครือข่าย เอดจ์จะส่งเอาต์พุตจากโหนดหนึ่งไปยังอินพุตของอีกโหนด ทำให้ข้อมูลสามารถไหลผ่านเครือข่ายได้ โหนดและเอดจ์ทำงานร่วมกันเพื่อประมวลผลและแปลงข้อมูลอินพุต ทำให้เกิดเอาต์พุตหรือการทำนายในท้ายที่สุด
weight คือพารามิเตอร์ของโครงข่ายประสาทเทียม เป็นค่าที่ปรับระหว่างกระบวนการฝึกอบรม(training)เพื่อเพิ่มประสิทธิภาพการทำงานของเครือข่าย แต่ละedgeในโครงข่ายประสาทเทียมมีweight ซึ่งแสดงถึงความแข็งแรงของการเชื่อมต่อระหว่างสองโหนด โดยทั่วไปแล้วweightจะเริ่มต้นด้วยค่าสุ่ม จากนั้นจึงปรับผ่านกระบวนการที่เรียกว่า backpropagation และ optimization algorithm ให้เหมาะสม เช่น gradient descent หรือ adam เป็นต้น เป้าหมายของการฝึกอบรมคือการค้นหา weight ที่เหมาะสมที่สุดที่ลดข้อผิดพลาดระหว่าง network prediction กับ ผลลัพธ์ที่ต้องการ
Backpropagation เป็นอัลกอริทึมที่ใช้ในการฝึกโครงข่ายประสาทเทียม(neural network) เป้าหมายของ backpropagation คือการปรับweightของเครือข่ายเพื่อลดข้อผิดพลาดระหว่าง network prediction กับ ผลลัพธ์ที่ต้องการ
กระบวนการเริ่มต้นด้วยการส่งต่อข้อมูล(forward pass) อินพุตจะถูกส่งผ่านnetwork และเอาต์พุตจะถูกสร้างขึ้นตามขั้นตอนปกติ จากนั้น error จะคำนวณโดยการเปรียบเทียบเอาต์พุตของnetwork กับเอาต์พุตที่ต้องการ จากนั้นจะเข้าสู่กระบวนการbackward ข้อผิดพลาด(error)จะถูกส่งกลับผ่านnetwork และ weight จะถูกปรับเพื่อลด error
กระบวนการนี้ทำได้โดยใช้กฎ chain rule ของแคลคูลัสเพื่อคำนวณ gradient ของerror ตามweight จากนั้นปรับปรุงweightในทิศทางตรงกันข้ามกับgradient กระบวนการนี้ทำซ้ำหลายครั้งจนกว่าข้อผิดพลาด(error)จะถึงระดับที่ยอมรับได้ อัลกอริทึมนี้เรียกว่า “backpropagation” เนื่องจากerrorถูก propagated กลับผ่านเครือข่าย จากเลเยอร์เอาต์พุตไปยังเลเยอร์อินพุต
Gradient descent เป็น optimization algorithm ที่ใช้เพื่อลดฟังก์ชัน เช่น error function ในโครงข่ายประสาทเทียม โดยทั่วไปจะใช้ในแมชชีนเลิร์นนิงและdeep learningเพื่อปรับ weight ของเครือข่ายเพื่อลดข้อผิดพลาด(error)ระหว่างการคาดการณ์ของเครือข่ายและเอาต์พุตที่ต้องการ
อัลกอริทึมทำงานโดยการอัปเดตweightซ้ำๆ ในทิศทาง negative gradient ของฟังก์ชัน error ซึ่งจะชี้ไปยังทิศทางของการลดลงที่ชันที่สุดของข้อผิดพลาด ในการวนซ้ำแต่ละครั้ง น้ำหนักจะอัปเดตตามสัดส่วนเล็กน้อยตามการไล่gradient ซึ่งเรียกว่า learning rate กระบวนการจะดำเนินต่อไปจนกว่าข้อผิดพลาด(error)จะถึงค่าต่ำสุดหรือถึงเกณฑ์การหยุด เช่น จำนวนการวนซ้ำสูงสุด
การไล่ระดับ gradient descent มีหลายรูปแบบ เช่น stochastic gradient descent, mini-batch gradient descent และmomentum-based gradient descent แต่ละรูปแบบเหล่านี้มีข้อดีและข้อเสียของตัวเอง และการเลือกใช้รูปแบบใดนั้นขึ้นอยู่กับปัญหาเฉพาะและทรัพยากรการคำนวณที่มีอยู่
learning rate คือไฮเปอร์พารามิเตอร์ที่ควบคุมขนาดขั้นตอนที่ optimizer ทำการอัพเดตพารามิเตอร์โมเดลระหว่างการฝึก เป็นค่าสเกลาร์(scalar)ที่คูณกับเกรเดียนต์ของ loss function ตามพารามิเตอร์โมเดลเพื่อกำหนดจำนวนการอัพเดต
learning rate ที่น้อยจะทำให้การเพิ่มประสิทธิภาพมาบรรจบกัน(optimization converge)ช้าๆ แต่จะทำให้แน่ใจว่าการเพิ่มประสิทธิภาพ(optimization)จะไม่เลยค่าต่ำสุด ในขณะที่learning rateที่มากขึ้นจะทำให้การเพิ่มประสิทธิภาพมาบรรจบกัน(optimization converge)เร็วขึ้น แต่อาจเลยค่าต่ำสุดและอาจ even diverge
learning rate ที่เหมาะสมเป็นสิ่งสำคัญของการฝึกอบรมโมเดลdeep learning หากอัตราการเรียนรู้น้อยเกินไป โมเดลจะบรรจบกันช้าเกินไปและอาจไปไม่ถึงโซลูชันที่เหมาะสมที่สุด(optimal solution) หากอัตราการเรียนรู้สูงเกินไป แบบจำลองอาจเกินโซลูชันที่เหมาะสมที่สุด (optimal solution) และผสานเข้ากับ suboptimal solution หรือ even diverge ดังนั้นควรกำหนดอัตราการเรียนรู้อย่างระมัดระวัง และเป็นเรื่องปกติที่จะใช้เทคนิคต่างๆ เช่น earning rate schedule หรือการลดอัตราการเรียนรู้(learning rate decay)เพื่อปรับอัตราการเรียนรู้ระหว่างการฝึกอบรม
Artificial Neural Network
Artificial Neural Network โครงข่ายประสาทเทียมเป็นอัลกอริธึมการเรียนรู้ของเครื่องประเภทหนึ่งที่ได้รับแรงบันดาลใจจากโครงสร้างของสมองมนุษย์ ประกอบด้วยชั้นของโหนดที่เชื่อมต่อกันซึ่งเรียกว่าเซลล์ประสาทเทียม เซลล์ประสาทแต่ละเซลล์ทำการคำนวณอย่างง่ายบนข้อมูลอินพุตและส่งผ่านผลลัพธ์ไปยังเซลล์ประสาทถัดไปในเครือข่าย
.ac2f31378926b5f99a4ba9d741c4aebe3b7a29e2.png)
โครงข่ายประสาทเทียมสามารถเรียนรู้รูปแบบและความสัมพันธ์ที่ซับซ้อนในข้อมูลได้โดยการปรับ weights และ bias ของการเชื่อมต่อระหว่างเซลล์ประสาท การฝึกอบรมโครงข่ายประสาทเทียมเกี่ยวข้องกับการปรับ weights และ bias เหล่านี้ตามข้อมูลอินพุตและเอาต์พุตที่ต้องการ เพื่อให้เครือข่ายสามารถเรียนรู้การทำงานเฉพาะได้
มีโครงข่ายประสาทเทียมหลายประเภท รวมถึงเครือข่าย Feedforward neural network (FNN), Convolutional neural networks(CNN) และ Recurrent neural networks(RNN) โครงข่ายประสาทเทียมแต่ละประเภทได้รับการออกแบบมาเพื่อทำงานเฉพาะด้านและเหมาะกับข้อมูลประเภทต่างๆ
โครงข่ายประสาทเทียมถูกนำมาใช้ในหลากหลายแอปพลิเคชัน รวมถึงการรู้จำภาพและคำพูด การประมวลผลภาษาธรรมชาติ และการตัดสินใจด้วยตนเอง สิ่งเหล่านี้เป็นส่วนสำคัญของปัญญาประดิษฐ์และคาดว่าจะมีผลกระทบอย่างมีนัยสำคัญต่อหลายแง่มุมของสังคมในอีกไม่กี่ปีข้างหน้า
Machine learning
machine learning เป็นปัญญาประดิษฐ์ประเภทหนึ่งที่เกี่ยวข้องกับการฝึกอัลกอริทึมเพื่อเรียนรู้จากข้อมูลและปรับปรุงประสิทธิภาพเมื่อเวลาผ่านไปโดยไม่ต้องตั้งโปรแกรมไว้อย่างชัดเจน โดยมีพื้นฐานมาจากแนวคิดที่ว่าระบบสามารถเรียนรู้จากข้อมูล ระบุรูปแบบ และทำการตัดสินใจหรือคาดการณ์โดยมีการแทรกแซงของมนุษย์น้อยที่สุด